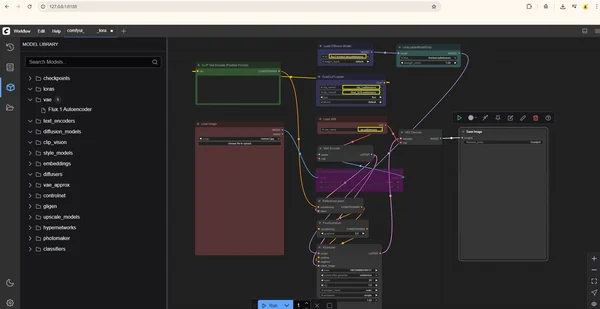
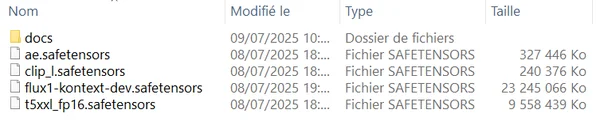
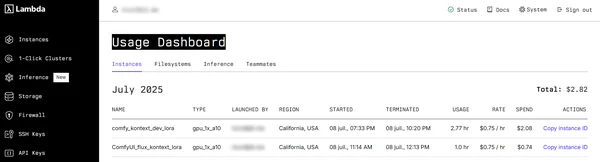
Using the raw Flux Kontext Dev open-weight model of 23GB with a LoRa on Lambda.ai cloud GPU.
I have the models stored on my own hard drive, and I upload them directly to the Lambda instance via Filebrowser through an SSH port forward on port 8080. I also expose the ComfyUI dashboard through the tunnel on port 8188.
Host LambdaComfy
Hostname 192.9.251.153 #ip lambalabs
User ubuntu
LocalForward 8080 127.0.0.1:8080
LocalForward 8188 127.0.0.1:8188
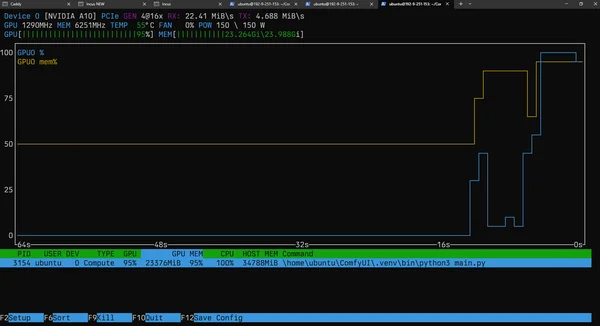
I'm using an Nvidia A10 with 24GB of VRAM. It's a bit tight for the full 23GB model, but it works... it takes about 1 to 2 minutes to generate an image.
Depending on your available VRAM
32GB VRAM --> Full-speed, full-precision model (24Go)
20GB VRAM --> FP8 quantized (12Go)
≤ 12GB VRAM --> Int8/GGUF small version (~5Go)
Install on Lambda.ai
$ git clone https://github.com/comfyanonymous/ComfyUI
$ curl -LsSf https://astral.sh/uv/install.sh | sh
$ uv add torch torchvision torchaudio
$ uv pip install -r requirements.txt
$ uv run main.py # run ComfyUI dash
$ curl -fsSL https://raw.githubusercontent.com/filebrowser/get/master/get.sh | bash
$ filebrowser -r ComfyUI/ # helping upload models