OBSERVE
Liminal space in a Japanese subway
A first-person psychological horror set in a Japanese train station after the last departure. The station knows your name. Something is watching. What is seen cannot be unseen. 終電後の日本の駅を舞台にした、一人称視点のサイコロジカルホラー。駅は、あなたの名前を知っている。何かが、見ている。一度見たものは、二度と見なか
Full keyboard
☇
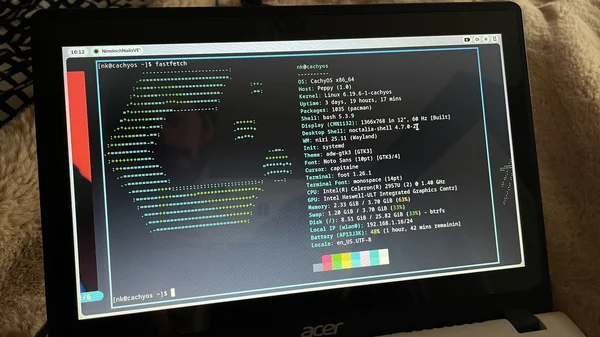
with 𝖼𝖺𝖼𝗁𝗒 ⁁ 𝗇𝗂𝗋𝗂 ⁁ 𝗇𝗈𝖼𝗍𝖺𝗅𝗂𝖺 ⁁ 𝗏𝗂𝗆𝗂𝗎𝗆
Ricing ⩆ Desktop Shell
𝖠𝗌𝗌𝖾𝗆𝖻𝗅𝗂𝗇𝗀 𝗒𝗈𝗎𝗋 *𝗇𝗂𝗑 𝖽𝖾𝗌𝗄𝗍𝗈𝗉
⚊⚊⚊
Status Bar
Waybar, Eww, scripts
C++, Rust, Shell/Python
Notifications
Mako, swaync, dunst
C, C++/Rust, C
Launcher
Rofi, wofi, fuzzel, tofi
C
Screen Locking
Swaylock, hyprlock, gtklock
C, C++, C
Idle Management
Swayidle, hypridle
C, C++
System Tools
htop, btop, nm-applet, blueman, pavucontrol
C, C++, C, Python, C++
Audio Control
pavucontrol, pamixer scripts
C++, Shell
Brightness Control
brightnessctl
C
Clipboard Manager
clipman, cliphist, wl-clipboard scripts Go, Go, Shell
Wallpaper
swaybg, swww, hyprpaper, wpaperd C, Rust, C++, Rust
Power Management
scripts Shell, Python
Greeter
gdm, sddm, lightdm, greetd C, C++, C, Rust
⚊⚊⚊
(Rice) Race Inspired Cosmetic Enhancement
レースに着想を得た美容強化

Void Linux
ultimate gigachad
⁁ independent : not based on any other distro just based
⁁ XBPS : package manager built for speed & reliability
⁁ minimalist : uses runit because systemd sucks
⁁ motto: i don't need donations, i need maintainers
* Allergic to Hyprland
MacOS
DE : Aqua
Theme : Liquid Glass
WM : Quartz Compositor
Windows
DE : Windows Shell
Theme : Fluent 2
WM : DWM
Ubuntu
DE : GNOME
Theme : Adwaita
WM : mutter
Debian
DE : KDE Plasma
Theme : Breeze
WM : KWin
Fedora
DS : Caelestia
∟components : Unified
Quickshell - QML/JS
𝖱𝖠𝖬 ~430𝖬𝗈
WM : Hyprland
Void Linux
DS : Vast
∟components : Unified
Quickshell - QML/JS
𝖱𝖠𝖬 ~430 𝖬𝗈
WM : Hyprland
Zirconium
DS : DMS
∟components : Unified
Quickshell - QML/JS
𝖱𝖠𝖬 ~370 𝖬𝗈
WM : Niri
CachyOS
DS : Noctalia
∟components : Unified
Quickshell - QML/JS
𝖱𝖠𝖬 ~300 𝖬𝗈
WM : Niri
Arch Linux
DS : eqSh
∟components : Unified
Quickshell - QML/JS
𝖱𝖠𝖬 ~330 𝖬𝗈
WM : Hyprland
Arch Linux
DS : Marble
∟components : Unified
AGS - JS/TypeScript
𝖱𝖠𝖬 ~300 𝖬𝗈
WM : Hyprland
Omarchy
DS : Omarchy
∟components : Fragmented
C, C++, Go, Rust
𝖱𝖠𝖬 ~180 𝖬𝗈
ʀɪᴄɪɴɢ-ᴅʜʜ
⋅ waybar (bar)
⋅ walker (launcher)
⋅ mako (notif)
⋅ hyprlock (lock)
⋅ hyprpaper (wallpaper)
⋅ wlogout (logout)
⋅ matugen (colors)
WM : Hyprland
• (DE) Desktop Environment
• (DS) Desktop Shell
• (Ricing) Race Inspired Cosmetic Enhancement

Agentic System
ᚔ ᚔ ᚔ ᚔ ᚔ ᚔ ᚔ
openclaw
☁ cloud ⚝ local (ollama)
claude computer
☁ cloud
zo computer
☁ cloud
perplexity computer
☁ cloud

I consider this the ultimate Wayland terminal.
It offers top-tier performance and ultra-low latency thanks to its CPU-based rendering.
At Just 40MB of RAM Usage.

Fiat x AI Agentic
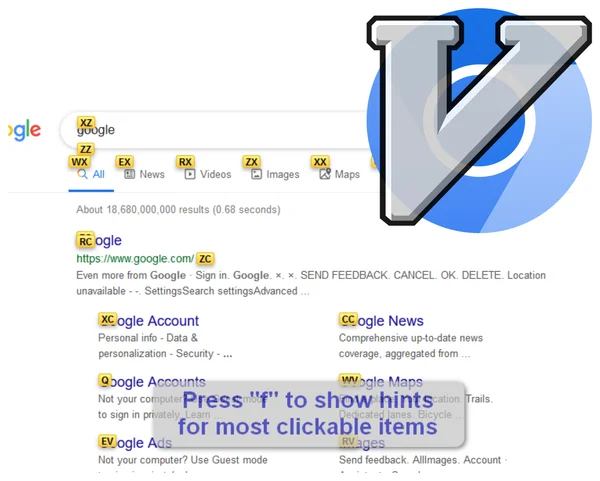
Vimium x Chrome
The Hacker's Browser
Vimium provides keyboard shortcuts for navigation and control in the spirit of Vim
install arch vanilla
install opencode
↳ build my os from scratch bro



The film follows a group of quantum physics students in Los Angeles who help a Catholic priest investigate an ancient cylinder of liquid discovered in a monastery, which they find out is a sentient liquid incarnation of the son of Satan

tmux
You're essentially running a terminal emulator nested inside another one.
As a result, every piece of data gets parsed twice, processed twice, and rendered twice :' )
Once through the terminal emulation layer
Once through the graphical interface

In an AI-driven world, "normal" routine skills get automated fast, leaving most folks scrambling.
To have a real future, lean into neurodivergence broadly, brains wired differently
⍨ ADHD
⍨ Autism
⍨ Dyslexia
Those let you think creatively, spot unique angles, build novel stuff like an artist, and innovate where AI can't.

weaponised autism